### Lifelong Learning: <br>Theory and Context PI: Joshua T. Vogelstein, [JHU](https://www.jhu.edu/) <br> Co-PI: Vova Braverman, [JHU](https://www.jhu.edu/) <br> Ali Geisa, Jayanta Dey, Will LeVine, Hayden Helm, Ronak Mehta, Carey E. Priebe <!-- | Joshua T. Vogelstein <br> --> <!-- [Microsoft Research](https://www.microsoft.com/en-us/research/): Weiwei Yang | Jonathan Larson | Bryan Tower | Chris White -->  --- ### Outline - background - theoretically motivate lifelong learning metrics - properly situation lifelong learning within hierarchy of learning paradigms --- class: middle # .center[Background] --- ### What is learning (Valiant)?  basically, doing better than chance with enough data  basically, doing arbitrarily well with enough data .ye[weak learning theorem states that if a problem is weakly learnable, then it is also strongly learnable] --- ### Limitations of this formal definition - there is only 1 task - requires large sample sizes for theory to be relevant - all data are from the same fixed distribution - evaluation is with respect to the data distribution --- ### What is learning (Mitchell)? A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E. -- Tom Mitchell, 1997 - Pro's - multiple tasks - uncouples experience (data) with tasks - explicit mention of improving due to data - implicitly requires transfer - Con's - not formalized --- class: middle # .center[Jovo Framework] --- ##### In-Distribution vs Out-of-Distribution Learning 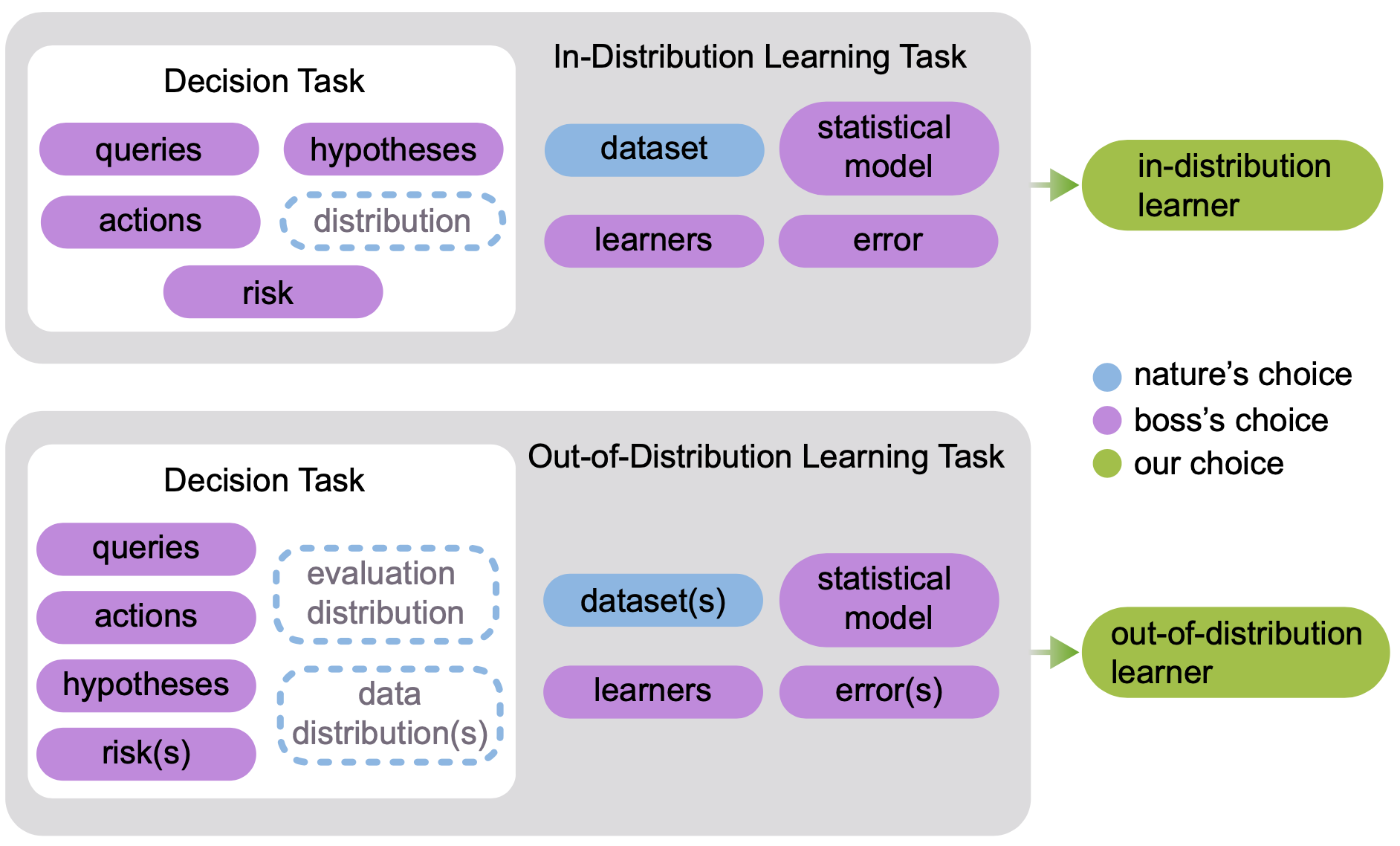 - the key differences - evaluation distribution is uncoupled from data distributions - multiple datasets & distributions --- ### Formalizing OOD Learnability  basically, using non-task data to improve performance at all 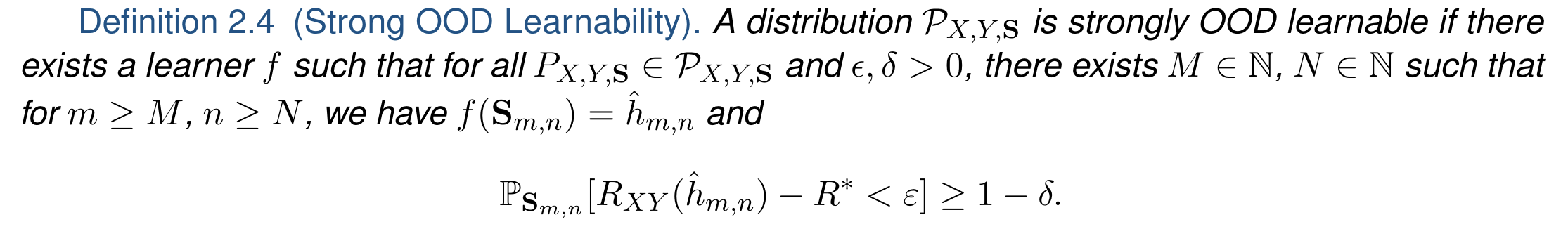 basically, using non-task data to perform arbitrarily well --- ### Quantifying learning The above two definitions enable one to assess .ye[whether] an agent $f$ has learned, but not .ye[how much] it learned.  basically, using non-task data to improve performance over what it could achieve using only task data --- ### Weak OOD Learner Theorem Theorem 1: With *only* out-of-distribution data, there exists some problems that are weakly, but not strongly, learnable. This implies that OOD learning is different *in kind* (and .ye[harder]) from in-distribution learning. <!-- - Lifelong learning is a special case of OOD learning. --> --- ### Transfer Learning Theorem Theorem 2: Weak OOD learnability implies transfer learnability (i.e., learning efficiency > 1). That is, if one can weakly learn, one can also transfer learn, but not necessarily vice versa. - This implies that transfer learnability is a fundamental property of learning problems - In other words, inability to transfer is equivalent to inability to learn at all. If one cannot transfer, one cannot learn in any meaningful sense. --- ### Learning Efficiency Applications Each of the previous definitions are all special cases of $LE^t_f(\mathbf{S}^A, \mathbf{S}^B)$, for specific choices of $\mathbf{S}^A$ and $\mathbf{S}^B$ - Learning: $\mathbf{S}^A=\mathbf{S}\_0$ and $\mathbf{S}^B=\mathbf{S}\_n$. - Transfer learning: $\mathbf{S}^A=\mathbf{S}\_n^t$ and $\mathbf{S}^B=\mathbf{S}\_n$. - Multitask learning: for each $t$, $\mathbf{S}^A=\mathbf{S}\_n^t$ and $\mathbf{S}^B=\mathbf{S}\_n$. - Forward learning: $\mathbf{S}^A=\mathbf{S}\_n^t$ and $\mathbf{S}^B=\mathbf{S}\_n^{< t}$. - Backward learning: $\mathbf{S}^A=\mathbf{S}\_n^{< t}$ and $\mathbf{S}^B=\mathbf{S}\_n$. --- ### Lifelong Learning $\subsetneq$ OOD learning 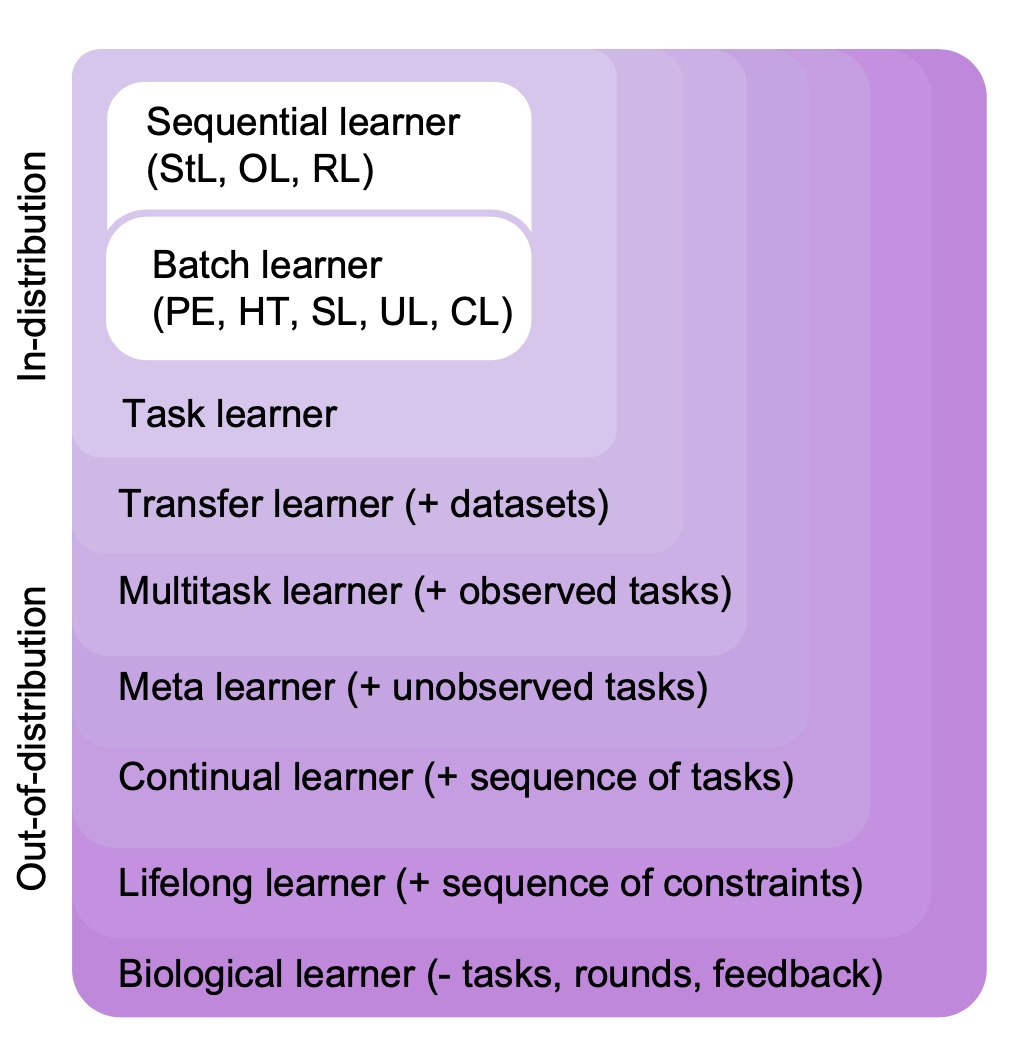 --- ### Biological learning is on top 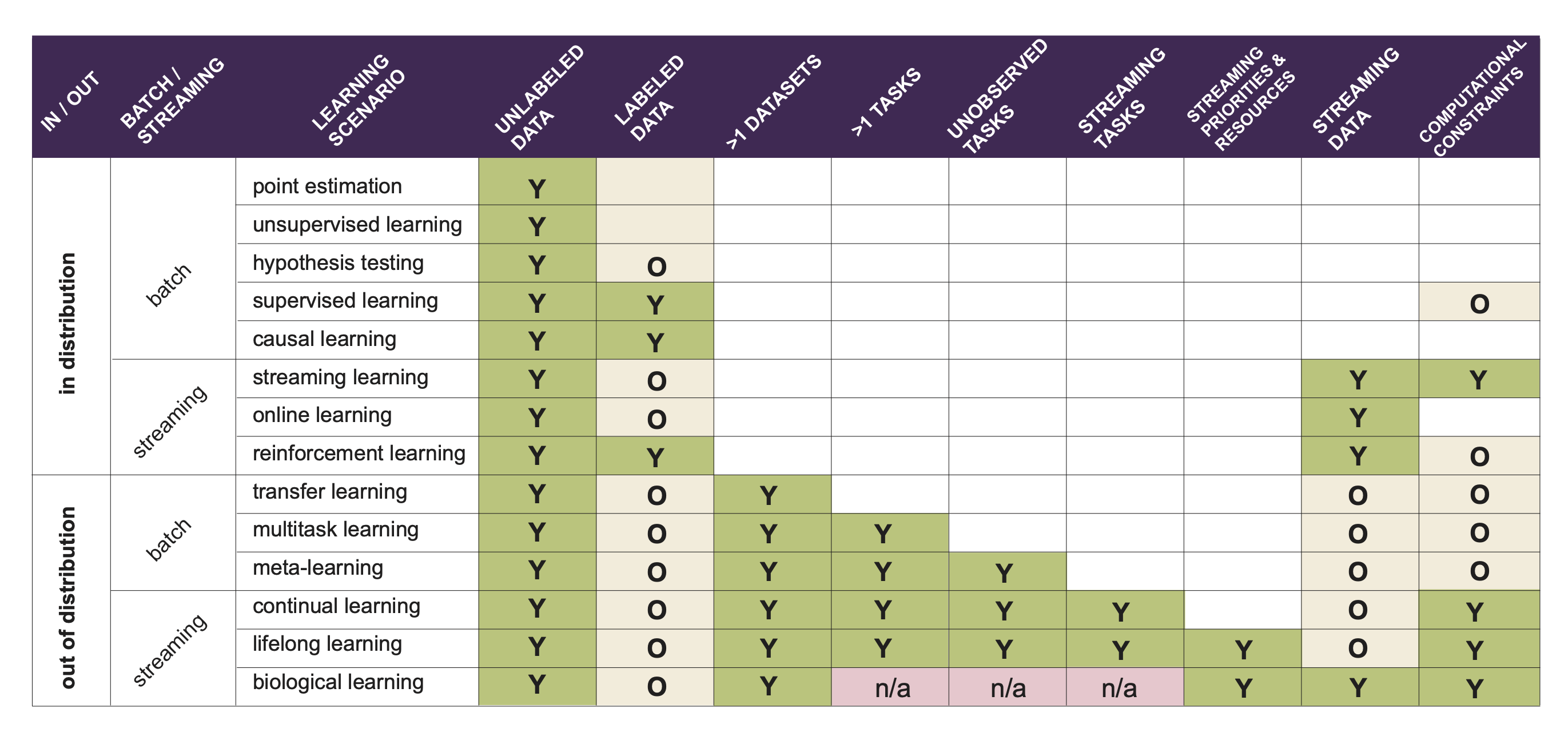 --- ### Discussion - unified definition and quantification of learning - presented hierarchy of learning paradigms - limitations of current framework: in biology, there are no tasks --- ### Transition Opportunities ### [http://proglearn.neurodata.io/](http://proglearn.neurodata.io/)  - code continues to improve (no time to discuss here) - ensembling representations (rather than decision rules) continues to be a promising path to solving OOD (including lifelong) and eventually biological learning --- ### Acknowledgements <!-- <div class="small-container"> <img src="faces/ebridge.jpg"/> <div class="centered">Eric Bridgeford</div> </div> <div class="small-container"> <img src="faces/pedigo.jpg"/> <div class="centered">Ben Pedigo</div> </div> <div class="small-container"> <img src="faces/jaewon.jpg"/> <div class="centered">Jaewon Chung</div> </div> --> <div class="small-container"> <img src="faces/yummy.jpg"/> <div class="centered">yummy</div> </div> <div class="small-container"> <img src="faces/lion.jpg"/> <div class="centered">lion</div> </div> <div class="small-container"> <img src="faces/violet.jpg"/> <div class="centered">owl</div> </div> <div class="small-container"> <img src="faces/family.jpg"/> <div class="centered">family</div> </div> <div class="small-container"> <img src="faces/earth.jpg"/> <div class="centered">earth</div> </div> <div class="small-container"> <img src="faces/milkyway.jpg"/> <div class="centered">milkyway</div> </div> ##### JHU <div class="small-container"> <img src="faces/cep.png"/> <div class="centered">Carey Priebe</div> </div> <!-- <div class="small-container"> <img src="faces/randal.jpg"/> <div class="centered">Randal Burns</div> </div> --> <!-- <div class="small-container"> <img src="faces/cshen.jpg"/> <div class="centered">Cencheng Shen</div> </div> --> <!-- <div class="small-container"> <img src="faces/bruce_rosen.jpg"/> <div class="centered">Bruce Rosen</div> </div> <div class="small-container"> <img src="faces/kent.jpg"/> <div class="centered">Kent Kiehl</div> </div> --> <!-- <div class="small-container"> <img src="faces/mim.jpg"/> <div class="centered">Michael Miller</div> </div> <div class="small-container"> <img src="faces/dtward.jpg"/> <div class="centered">Daniel Tward</div> </div> --> <!-- <div class="small-container"> <img src="faces/vikram.jpg"/> <div class="centered">Vikram Chandrashekhar</div> </div> <div class="small-container"> <img src="faces/drishti.jpg"/> <div class="centered">Drishti Mannan</div> </div> --> <!-- <div class="small-container"> <img src="faces/jesse.jpg"/> <div class="centered">Jesse Patsolic</div> </div> --> <!-- <div class="small-container"> <img src="faces/falk_ben.jpg"/> <div class="centered">Benjamin Falk</div> </div> --> <!-- <div class="small-container"> <img src="faces/kwame.jpg"/> <div class="centered">Kwame Kutten</div> </div> --> <!-- <div class="small-container"> <img src="faces/perlman.jpg"/> <div class="centered">Eric Perlman</div> </div> --> <!-- <div class="small-container"> <img src="faces/loftus.jpg"/> <div class="centered">Alex Loftus</div> </div> --> <!-- <div class="small-container"> <img src="faces/bcaffo.jpg"/> <div class="centered">Brian Caffo</div> </div> --> <!-- <div class="small-container"> <img src="faces/minh.jpg"/> <div class="centered">Minh Tang</div> </div> --> <!-- <div class="small-container"> <img src="faces/avanti.jpg"/> <div class="centered">Avanti Athreya</div> </div> --> <!-- <div class="small-container"> <img src="faces/vince.jpg"/> <div class="centered">Vince Lyzinski</div> </div> --> <!-- <div class="small-container"> <img src="faces/dpmcsuss.jpg"/> <div class="centered">Daniel Sussman</div> </div> --> <!-- <div class="small-container"> <img src="faces/youngser.jpg"/> <div class="centered">Youngser Park</div> </div> --> <!-- <div class="small-container"> <img src="faces/shangsi.jpg"/> <div class="centered">Shangsi Wang</div> </div> --> <!-- <div class="small-container"> <img src="faces/tyler.jpg"/> <div class="centered">Tyler Tomita</div> </div> --> <!-- <div class="small-container"> <img src="faces/james.jpg"/> <div class="centered">James Brown</div> </div> --> <!-- <div class="small-container"> <img src="faces/disa.jpg"/> <div class="centered">Disa Mhembere</div> </div> --> <!-- <div class="small-container"> <img src="faces/gkiar.jpg"/> <div class="centered">Greg Kiar</div> </div> --> <!-- <div class="small-container"> <img src="faces/jeremias.png"/> <div class="centered">Jeremias Sulam</div> </div> --> <div class="small-container"> <img src="faces/meghana.png"/> <div class="centered">Meghana Madhya</div> </div> <!-- <div class="small-container"> <img src="faces/percy.png"/> <div class="centered">Percy Li</div> </div> --> <div class="small-container"> <img src="faces/ronak.jpg"/> <div class="centered">Ronak Mehta</div> </div> <div class="small-container"> <img src="faces/jayanta.jpg"/> <div class="centered">Jayanta Dey</div> </div> <div class="small-container"> <img src="faces/will.jpg"/> <div class="centered">Will LeVine</div> </div> <div class="small-container"> <img src="faces/hayden.png"/> <div class="centered">Hayden Helm</div> </div> <div class="small-container"> <img src="faces/rguo.jpg"/> <div class="centered">Richard Gou</div> </div> <div class="small-container"> <img src="faces/alig.jpg"/> <div class="centered">Ali Geisa</div> </div> ##### Microsoft Research <div class="small-container"> <img src="faces/chwh-180x180.jpg"/> <div class="centered">Chris White</div> </div> <div class="small-container"> <img src="faces/weiwei.jpg"/> <div class="centered">Weiwei Yang</div> </div> <div class="small-container"> <img src="faces/jolarso150px.png"/> <div class="centered">Jonathan Larson</div> </div> <div class="small-container"> <img src="faces/brtower-180x180.jpg"/> <div class="centered">Bryan Tower</div> </div> ##### DARPA L2M: All code open source and reproducible from [proglearn.neurodata.io/](http://proglearn.neurodata.io/) <!-- Hava, Ben, Robert, Jennifer, Ted. --> {[BME](https://www.bme.jhu.edu/),[CIS](http://cis.jhu.edu/), [ICM](https://icm.jhu.edu/), [KNDI](http://kavlijhu.org/)}@[JHU](https://www.jhu.edu/) | [neurodata](https://neurodata.io) <br> [jovo@jhu.edu](mailto:j1c@jhu.edu) | <http://neurodata.io/talks> | [@neuro_data](https://twitter.com/neuro_data) </div> <!-- <img src="images/funding/nsf_fpo.png" STYLE="HEIGHT:95px;"/> --> <!-- <img src="images/funding/nih_fpo.png" STYLE="HEIGHT:95px;"/> --> <!-- <img src="images/funding/darpa_fpo.png" STYLE=" HEIGHT:95px;"/> --> <!-- <img src="images/funding/iarpa_fpo.jpg" STYLE="HEIGHT:95px;"/> --> <!-- <img src="images/funding/KAVLI.jpg" STYLE="HEIGHT:95px;"/> --> <!-- <img src="images/funding/schmidt.jpg" STYLE="HEIGHT:95px;"/> --> --- background-image: url(images/l_and_v.jpeg) .footnote[Questions?]